Code
library(ggplot2)
library(data.table)
library(patchwork)
base_dir <- here::here()
source(file.path(base_dir, "sim-analyze.R"))
mcols <- method_colors()
mlabs <- method_labels()
dlabs <- dgp_short_labels()Registration Benchmark v2
library(ggplot2)
library(data.table)
library(patchwork)
base_dir <- here::here()
source(file.path(base_dir, "sim-analyze.R"))
mcols <- method_colors()
mlabs <- method_labels()
dlabs <- dgp_short_labels()dt <- load_study_d()oracle_keys <- c("dgp", "method", "condition")
warp_mode_ratio <- ratio_to_baseline(
dt = dt,
metric = "warp_mise",
by = c(oracle_keys, "template_mode"),
baseline_col = "template_mode",
baseline_level = "estimated",
stat = "median",
value_name = "warp_mise",
baseline_name = "estimated",
ratio_name = "oracle_ratio",
keep_baseline = TRUE
)
benefit_wide <- warp_mode_ratio[
template_mode == "oracle",
.(
dgp, method, condition,
estimated,
oracle = warp_mise,
pct_improvement = 100 * (1 - oracle_ratio)
)
]
ae_mode_ratio <- ratio_to_baseline(
dt = dt,
metric = "alignment_error",
by = c(oracle_keys, "template_mode"),
baseline_col = "template_mode",
baseline_level = "estimated",
stat = "median",
value_name = "alignment_error",
baseline_name = "estimated",
ratio_name = "oracle_ratio",
keep_baseline = TRUE
)
ae_benefit_wide <- ae_mode_ratio[
template_mode == "oracle",
.(
dgp, method, condition,
estimated,
oracle = alignment_error,
pct_improvement = 100 * (1 - oracle_ratio)
)
]
benefit_rep <- dt[
failure == FALSE,
.(dgp, method, condition, rep, template_mode, warp_mise)
]
benefit_rep_wide <- dcast(
benefit_rep,
dgp + method + condition + rep ~ template_mode,
value.var = "warp_mise"
)
benefit_rep_wide[, pct_improvement := 100 * (estimated - oracle) / estimated]
cond_plot_dt <- benefit_rep_wide[, .(
pct_improvement = median(pct_improvement, na.rm = TRUE),
q25 = quantile(pct_improvement, 0.25, na.rm = TRUE),
q75 = quantile(pct_improvement, 0.75, na.rm = TRUE)
), by = .(dgp, method, condition)]
ae_benefit_rep <- dt[
failure == FALSE,
.(dgp, method, condition, rep, template_mode, alignment_error)
]
ae_benefit_rep_wide <- dcast(
ae_benefit_rep,
dgp + method + condition + rep ~ template_mode,
value.var = "alignment_error"
)
ae_benefit_rep_wide[, pct_improvement := 100 * (estimated - oracle) / estimated]Study D decomposes total registration error into template estimation error vs warp estimation error. When given the true template (oracle mode), template MISE = 0 and any remaining warp MISE is purely from the warp estimation algorithm.
Design: 6 DGPs \(\times\) 2 template modes (oracle, estimated) \(\times\) 2 conditions \(\times\) 5 methods = 120 cells \(\times\) 50 reps = 6,000 runs.
Two conditions:
| Condition | Noise | Severity | Purpose |
|---|---|---|---|
| Easy | 0.1 | 0.5 | Anchor: template estimation is relatively easy |
| Hard | 0.3 | 1.0 | Stress: high noise + large warps stress iterative estimation |
Important caveat: The oracle and estimated pipelines differ not only in template source but also in the number of Procrustes iterations (see Section 7 for details). The oracle comparison therefore reflects the joint effect of template quality and iterative refinement, not a pure template-only ablation.
dgps_used <- c("D01", "D03", "D09", "D10", "D13", "D14")
knitr::kable(
dgp_factors()[dgp %in% dgps_used],
caption = "DGPs in Study D: 6 DGPs spanning both templates, all 3 warp types, and none/highrank amplitude."
)| dgp | template | warp_type | amplitude |
|---|---|---|---|
| D01 | harmonic | simple | none |
| D03 | wiggly | complex | none |
| D09 | harmonic | simple | highrank |
| D10 | harmonic | complex | highrank |
| D13 | wiggly | affine | highrank |
| D14 | wiggly | simple | none |
Template MISE should be exactly 0 (or numerically negligible) in oracle mode for template-based methods, since the true template is passed directly. Landmark registration ignores the supplied template (it aligns to detected landmarks), so its template MISE is nonzero even in oracle mode — this is expected.
tmise <- dt[failure == FALSE,
.(template_mise = median(template_mise, na.rm = TRUE)),
by = .(template_mode, method)
]
tmise_wide <- dcast(tmise, method ~ template_mode, value.var = "template_mise")
tmise_wide[, method := mlabs[method]]
cat("**Median template MISE by mode:**\n\n")Median template MISE by mode:
print(knitr::kable(tmise_wide, digits = 8))| method | estimated | oracle |
|---|---|---|
| SRVF | 0.0944 | 0.000 |
| CC (FPC1 cc) | 0.1025 | 0.000 |
| CC (L2 dist) | 0.0586 | 0.000 |
| Affine (S+S) | 0.0637 | 0.000 |
| Landmark (auto) | 0.1576 | 0.158 |
oracle_max_no_lm <- dt[
use_true_template == TRUE & failure == FALSE & method != "landmark_auto",
max(template_mise, na.rm = TRUE)
]
cat(sprintf(
"\nMax template MISE in oracle mode (excluding landmarks): %.2e (expect ~0).\n\n",
oracle_max_no_lm
))Max template MISE in oracle mode (excluding landmarks): 0.00e+00 (expect ~0).
Landmark registration does not use a template estimate — it aligns to detected landmarks. The oracle benefit for landmarks should be exactly 0 (serving as a negative control).
lm_dt <- dt[method == "landmark_auto" & failure == FALSE,
.(warp_mise = median(warp_mise, na.rm = TRUE)),
by = .(template_mode, condition)
]
lm_wide <- dcast(lm_dt, condition ~ template_mode, value.var = "warp_mise")
lm_wide[, diff := estimated - oracle]
cat("**Landmark warp MISE by condition and template mode:**\n\n")Landmark warp MISE by condition and template mode:
print(knitr::kable(lm_wide, digits = 6))| condition | estimated | oracle | diff |
|---|---|---|---|
| easy | 0.00287 | 0.00287 | 0 |
| hard | 0.01794 | 0.01794 | 0 |
fail_dt <- dt[,
.(n_fail = sum(failure), n_total = .N, rate = mean(failure)),
by = .(method, template_mode)
]
fail_any <- fail_dt[n_fail > 0]
if (nrow(fail_any) == 0) {
cat("No failures across all 6,000 runs.\n\n")
} else {
cat("**Failure rates by method and template mode:**\n\n")
print(knitr::kable(fail_dt[n_fail > 0], digits = 3))
}Failure rates by method and template mode:
| method | template_mode | n_fail | n_total | rate |
|---|---|---|---|---|
| landmark_auto | oracle | 5 | 600 | 0.008 |
| landmark_auto | estimated | 5 | 600 | 0.008 |
Oracle benefit = warp MISE (estimated template) \(-\) warp MISE (oracle template). Positive values mean the oracle helps (lower warp error with true template). Negative values mean the estimated-template pipeline produces lower warp error than the oracle pipeline — see Section 3.3 for interpretation.
ggplot(benefit_wide, aes(x = method, y = dgp, fill = pct_improvement)) +
geom_tile(color = "white", linewidth = 0.5) +
geom_label(aes(label = sprintf("%.0f%%", pct_improvement)),
size = 2.3, fill = "white", alpha = 0.85,
label.size = 0, label.padding = unit(1.5, "pt")) +
facet_wrap(~condition) +
scale_x_discrete(labels = mlabs) +
scale_y_discrete(labels = dlabs) +
scale_fill_gradient2(
low = "#2166AC", mid = "grey95", high = "#B2182B",
midpoint = 0, name = "Oracle\nbenefit (%)",
limits = c(-170, 100),
oob = scales::squish
) +
labs(x = NULL, y = NULL,
subtitle = "Oracle benefit: % improvement in warp MISE when given true template") +
theme_benchmark()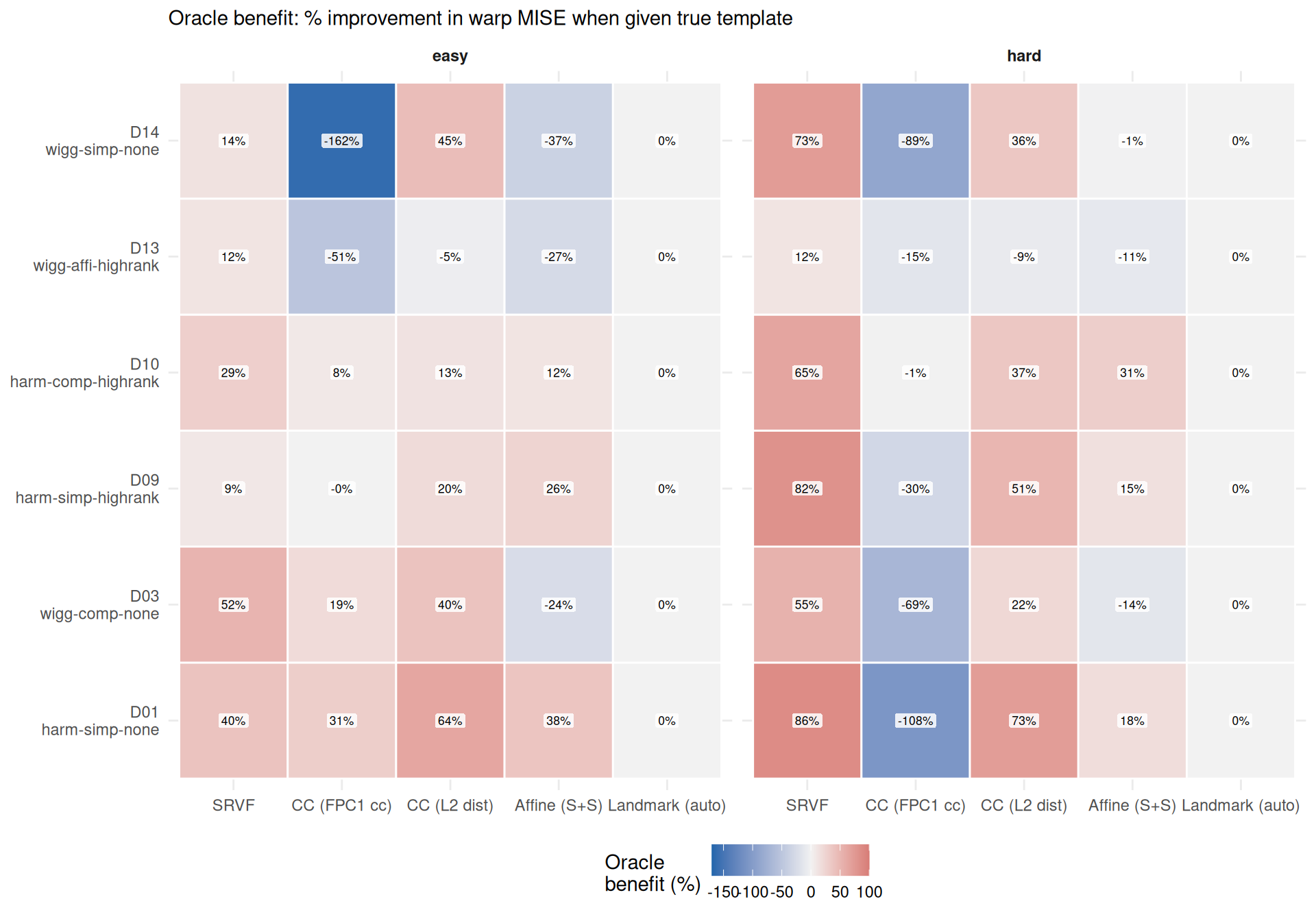
ggplot(benefit_wide[method != "landmark_auto"],
aes(x = pct_improvement, y = method, color = method)) +
geom_vline(xintercept = 0, linetype = "dashed", color = "grey40") +
geom_jitter(height = 0.15, size = 2.5, alpha = 0.7) +
stat_summary(fun = median, geom = "crossbar", width = 0.4,
color = "black", linewidth = 0.4) +
facet_wrap(~condition) +
scale_color_manual(values = mcols, guide = "none") +
scale_y_discrete(labels = mlabs) +
labs(x = "Oracle benefit (% improvement in warp MISE)", y = NULL) +
theme_benchmark()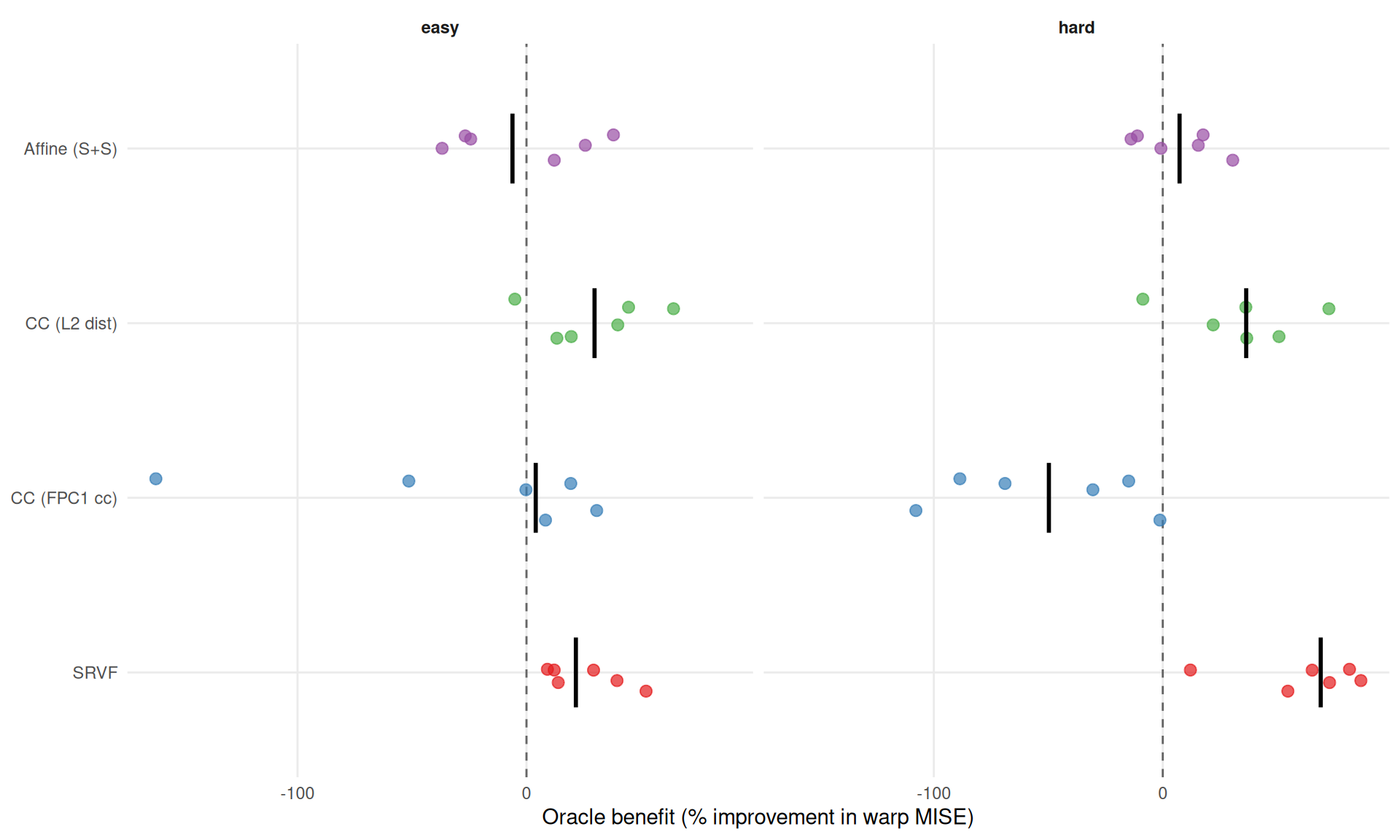
method_summary <- benefit_wide[method != "landmark_auto",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0,
median_pct = median(pct_improvement, na.rm = TRUE),
min_pct = min(pct_improvement, na.rm = TRUE),
max_pct = max(pct_improvement, na.rm = TRUE)
),
by = .(method, condition)
]
cat("**Oracle benefit by method** (% improvement in warp MISE):\n\n")Oracle benefit by method (% improvement in warp MISE):
for (cond in c("easy", "hard")) {
cat(sprintf("*%s condition (noise=%s, severity=%s):*\n\n",
cond,
ifelse(cond == "easy", "0.1", "0.3"),
ifelse(cond == "easy", "0.5", "1.0")))
sub <- method_summary[condition == cond][order(-median_pct)]
for (i in seq_len(nrow(sub))) {
cat(sprintf("- **%s**: mean %.0f ± %.0f pp; median %.0f%% [%.0f%%, %.0f%%]\n",
mlabs[sub$method[i]],
sub$mean_pct[i], sub$se_pct[i],
sub$median_pct[i], sub$min_pct[i], sub$max_pct[i]))
}
cat("\n")
}easy condition (noise=0.1, severity=0.5):
hard condition (noise=0.3, severity=1.0):
fda_def <- benefit_wide[method == "cc_default"]
n_negative <- sum(fda_def$pct_improvement < 0)
n_total_fda <- nrow(fda_def)
worst <- fda_def[which.min(pct_improvement)]
fda_def_by_cond <- fda_def[, .(
n_negative = sum(pct_improvement < 0),
n_total = .N,
mean_pct = mean(pct_improvement),
se_pct = if (.N > 1) sd(pct_improvement) / sqrt(.N) else 0,
median_pct = median(pct_improvement)
), by = condition]
cat(sprintf(
"**cc_default** shows negative oracle benefit in %d of %d DGP-condition cells ",
n_negative, n_total_fda
))cc_default shows negative oracle benefit in 9 of 12 DGP-condition cells
cat(sprintf(
"(worst: %s %s condition, %.0f%%).\n\n",
worst$dgp, worst$condition, worst$pct_improvement
))(worst: D14 easy condition, -162%).
cat("By condition, the hard regime is more uniformly negative, while the easy regime is mixed and skewed:\n\n")By condition, the hard regime is more uniformly negative, while the easy regime is mixed and skewed:
for (i in seq_len(nrow(fda_def_by_cond))) {
r <- fda_def_by_cond[i]
cat(sprintf(
"- **%s**: %d/%d cells negative; mean oracle benefit %.0f ± %.0f pp; median %.0f%%\n",
r$condition, r$n_negative, r$n_total,
r$mean_pct, r$se_pct, r$median_pct
))
}cat("\n")cat("This means the estimated-template pipeline produces *lower* warp MISE than the ",
"oracle pipeline. Two factors contribute:\n\n")This means the estimated-template pipeline produces lower warp MISE than the oracle pipeline. Two factors contribute:
cat("1. **Iteration confound** (@sec-limitations): The estimated pipeline runs ",
"10 Procrustes iterations (jointly refining template and warps), while the oracle ",
"pipeline runs only 1 (since `tf` sets `max_iter = 1` when a template is provided). ",
"The additional iterations improve warp estimates even though the template is less accurate.\n\n")tf sets max_iter = 1 when a template is provided). The additional iterations improve warp estimates even though the template is less accurate.cat("2. **Objective mismatch**: cc_default uses criterion 2 (eigenfunction-based), ",
"which may converge to a biased template that happens to be easier for its ",
"warping objective to fit. The iteratively estimated template is co-adapted to ",
"the warping criterion, whereas the true template is not.\n\n")# Compare with cc_crit1
crit1_neg <- benefit_wide[method == "cc_crit1", sum(pct_improvement < 0)]
cat(sprintf(
"By contrast, **cc_crit1** (criterion 1, ISE-based) shows negative oracle benefit ",
"in only %d of %d cells, suggesting criterion 2 is more sensitive to the ",
"iteration/co-adaptation effect.\n",
crit1_neg, nrow(benefit_wide[method == "cc_crit1"])
))By contrast, cc_crit1 (criterion 1, ISE-based) shows negative oracle benefit
ggplot(cond_plot_dt[method != "landmark_auto"],
aes(x = condition, y = pct_improvement, group = interaction(method, dgp),
color = method)) +
geom_line(alpha = 0.5) +
geom_point(size = 2) +
geom_errorbar(aes(ymin = q25, ymax = q75), width = 0.08, alpha = 0.3) +
facet_wrap(~method, labeller = labeller(method = mlabs)) +
scale_color_manual(values = mcols, guide = "none") +
labs(x = "Condition", y = "Oracle benefit (%)") +
theme_benchmark()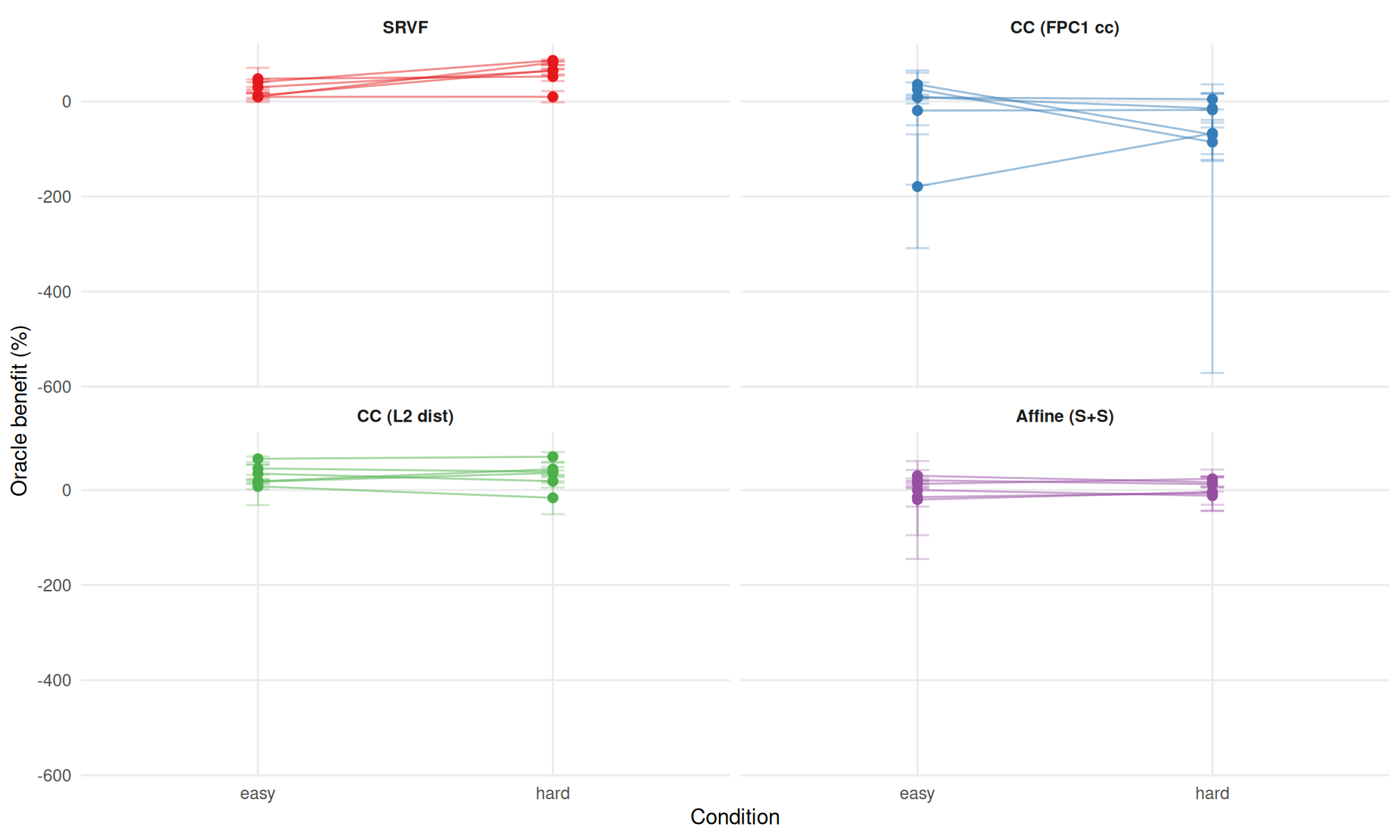
cond_change <- dcast(method_summary, method ~ condition, value.var = "mean_pct")
cond_se <- dcast(method_summary, method ~ condition, value.var = "se_pct")
cond_change[, change := hard - easy]
cat("**Does oracle benefit grow from easy to hard?**\n\n")Does oracle benefit grow from easy to hard?
for (i in seq_len(nrow(cond_change))) {
m <- cond_change$method[i]
cat(sprintf("- **%s**: easy %.0f ± %.0f pp → hard %.0f ± %.0f pp (%+.0f pp)\n",
mlabs[m],
cond_change$easy[i], cond_se$easy[i],
cond_change$hard[i], cond_se$hard[i],
cond_change$change[i]
))
}cat("\n")# Check if effect is method-dependent
n_pos <- sum(cond_change$change > 0)
n_neg <- sum(cond_change$change < 0)
cat(sprintf(
"The condition effect is method-dependent: %d methods show increased oracle ",
n_pos
))The condition effect is method-dependent: 3 methods show increased oracle
cat(sprintf(
"benefit under the hard condition, while %d show decreased (or more negative) ",
n_neg
))benefit under the hard condition, while 1 show decreased (or more negative)
cat("benefit. For SRVF, harder conditions amplify the oracle benefit as expected. ",
"For cc_default, the negative oracle benefit persists or worsens, consistent ",
"with the iteration confound (@sec-limitations).\n")benefit. For SRVF, harder conditions amplify the oracle benefit as expected. For cc_default, the negative oracle benefit persists or worsens, consistent with the iteration confound (Section 7).
Direct comparison of warp MISE under oracle and estimated template modes.
ggplot(
dt[failure == FALSE & method != "landmark_auto"],
aes(y = template_mode, x = warp_mise, fill = template_mode)
) +
geom_boxplot(outlier.size = 0.3, outlier.alpha = 0.2) +
facet_grid(method ~ condition,
scales = "free_x",
labeller = labeller(method = mlabs)) +
scale_fill_manual(
values = c(estimated = "#F0E442", oracle = "#56B4E9"),
guide = "none"
) +
scale_x_log10() +
labs(y = NULL, x = "Warp MISE (log scale)") +
theme_benchmark()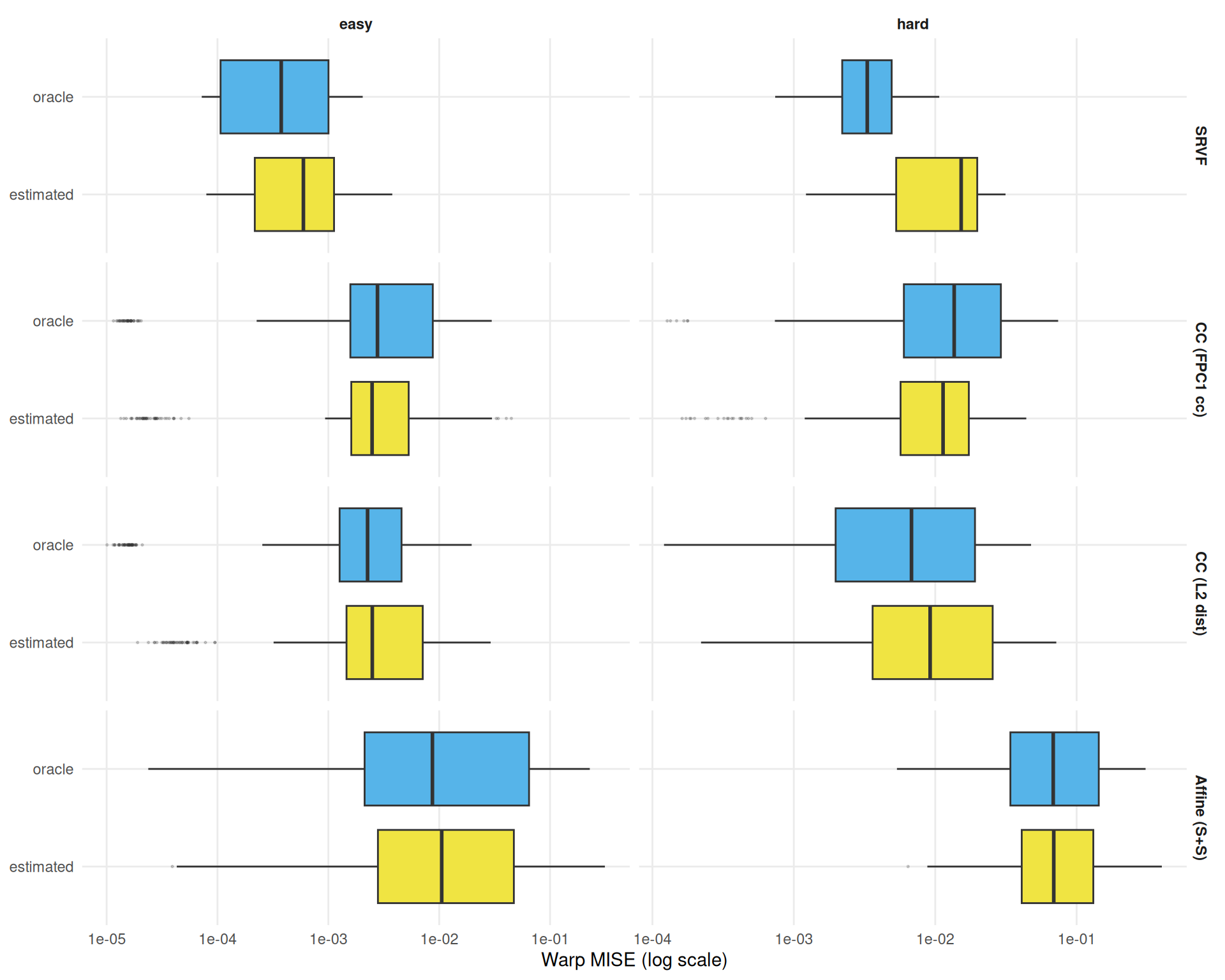
dgp_comp <- dt[failure == FALSE & method != "landmark_auto",
.(
median = median(warp_mise, na.rm = TRUE),
q25 = quantile(warp_mise, 0.25, na.rm = TRUE),
q75 = quantile(warp_mise, 0.75, na.rm = TRUE)
),
by = .(dgp, method, template_mode, condition)
]
ggplot(dgp_comp, aes(x = template_mode, y = median, fill = template_mode)) +
geom_col(position = "dodge", width = 0.7) +
geom_errorbar(aes(ymin = q25, ymax = q75), width = 0.2, alpha = 0.5) +
facet_grid(dgp ~ method + condition,
scales = "free_y",
labeller = labeller(method = mlabs, dgp = dlabs)) +
scale_fill_manual(
values = c(estimated = "#F0E442", oracle = "#56B4E9"),
name = "Template"
) +
scale_y_log10() +
labs(x = NULL, y = "Warp MISE (log scale)") +
theme_benchmark(base_size = 8) +
theme(axis.text.x = element_blank())
Alignment error measures \(\text{mean}_i \int (\hat{x}_i^{\text{aligned}} - \tilde{x}_i)^2\,dt\) — the practical downstream impact of registration quality. Does knowing the true template also improve alignment of registered curves?
ggplot(ae_benefit_wide, aes(x = method, y = dgp, fill = pct_improvement)) +
geom_tile(color = "white", linewidth = 0.5) +
geom_label(aes(label = sprintf("%.0f%%", pct_improvement)),
size = 2.3, fill = "white", alpha = 0.85,
label.size = 0, label.padding = unit(1.5, "pt")) +
facet_wrap(~condition) +
scale_x_discrete(labels = mlabs) +
scale_y_discrete(labels = dlabs) +
scale_fill_gradient2(
low = "#2166AC", mid = "grey95", high = "#B2182B",
midpoint = 0, name = "Oracle\nbenefit (%)",
limits = c(-170, 100),
oob = scales::squish
) +
labs(x = NULL, y = NULL,
subtitle = "Oracle benefit: % improvement in alignment error when given true template") +
theme_benchmark()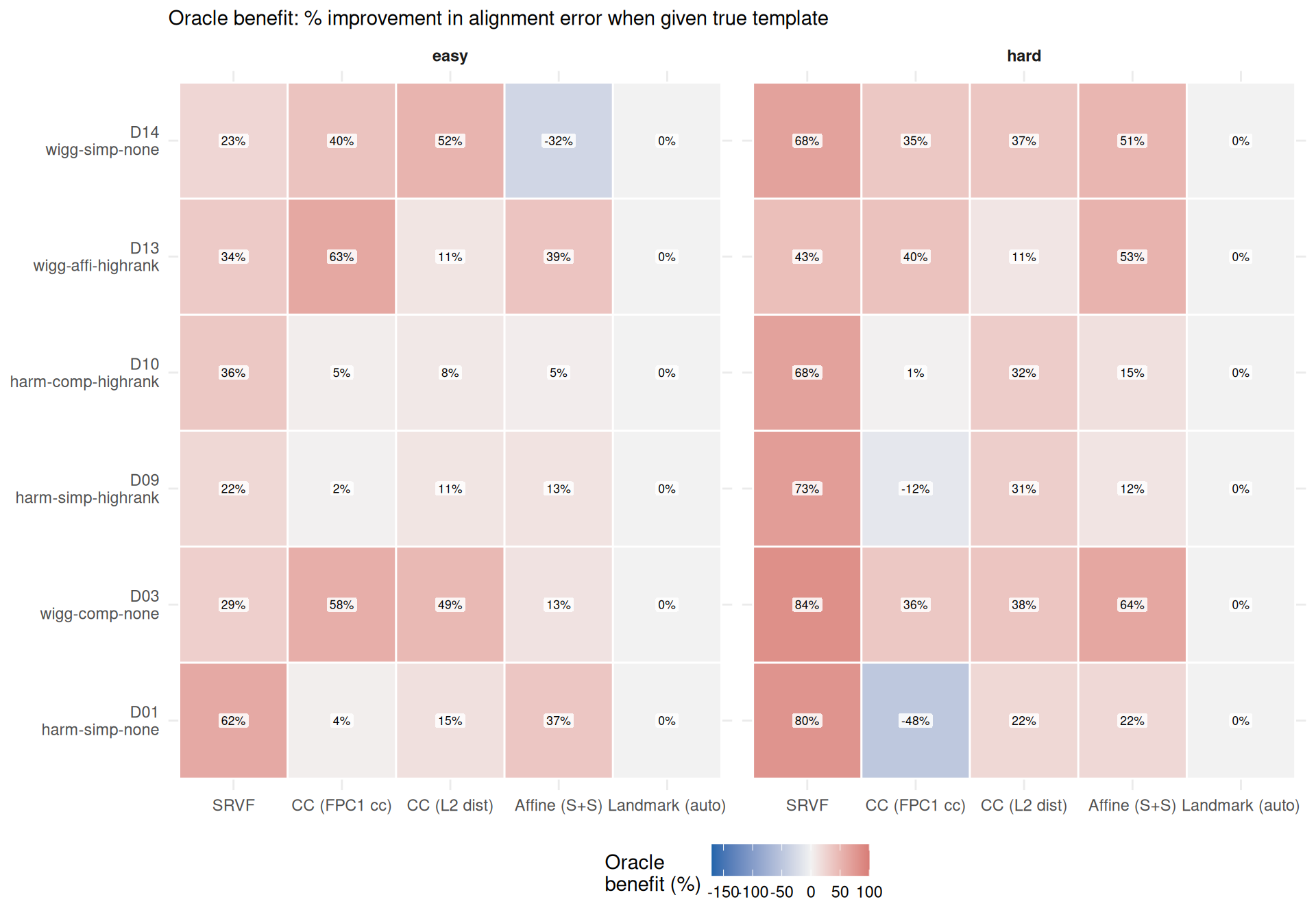
ggplot(ae_benefit_wide[method != "landmark_auto"],
aes(x = pct_improvement, y = method, color = method)) +
geom_vline(xintercept = 0, linetype = "dashed", color = "grey40") +
geom_jitter(height = 0.15, size = 2.5, alpha = 0.7) +
stat_summary(fun = median, geom = "crossbar", width = 0.4,
color = "black", linewidth = 0.4) +
facet_wrap(~condition) +
scale_color_manual(values = mcols, guide = "none") +
scale_y_discrete(labels = mlabs) +
labs(x = "Oracle benefit (% improvement in alignment error)", y = NULL) +
theme_benchmark()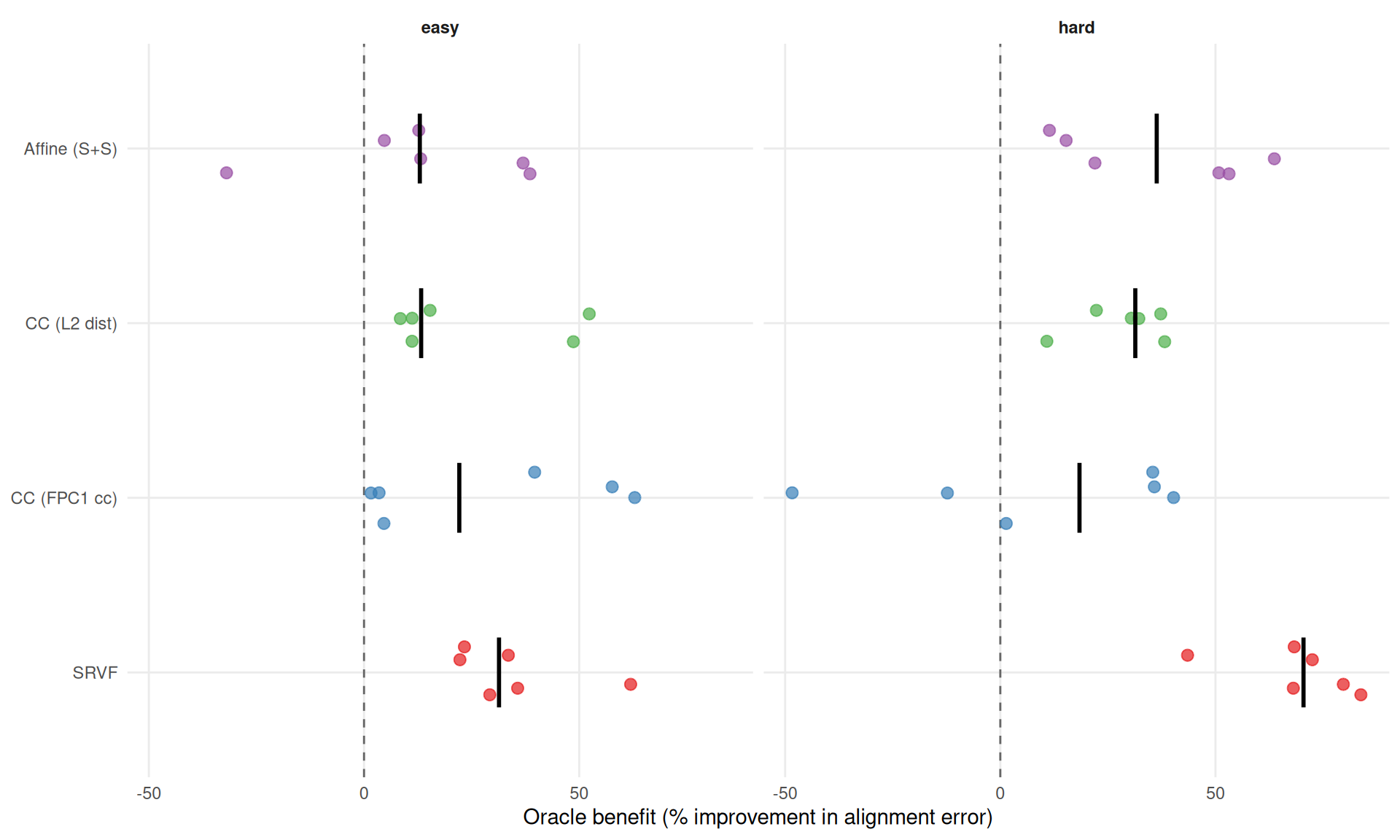
ae_method_summary <- ae_benefit_wide[method != "landmark_auto",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0,
median_pct = median(pct_improvement, na.rm = TRUE),
min_pct = min(pct_improvement, na.rm = TRUE),
max_pct = max(pct_improvement, na.rm = TRUE)
),
by = .(method, condition)
]
cat("**Alignment error oracle benefit by method:**\n\n")Alignment error oracle benefit by method:
for (cond in c("easy", "hard")) {
cat(sprintf("*%s condition:*\n\n", cond))
sub <- ae_method_summary[condition == cond][order(-median_pct)]
for (i in seq_len(nrow(sub))) {
cat(sprintf("- **%s**: mean %.0f ± %.0f pp; median %.0f%% [%.0f%%, %.0f%%]\n",
mlabs[sub$method[i]],
sub$mean_pct[i], sub$se_pct[i],
sub$median_pct[i], sub$min_pct[i], sub$max_pct[i]))
}
cat("\n")
}easy condition:
hard condition:
# Compare with warp MISE oracle benefit
warp_benefit_sub <- benefit_wide[method != "landmark_auto",
.(method, dgp, condition, warp_pct = pct_improvement)]
ae_benefit_sub <- ae_benefit_wide[method != "landmark_auto",
.(method, dgp, condition, ae_pct = pct_improvement)]
both <- merge(warp_benefit_sub, ae_benefit_sub,
by = c("method", "dgp", "condition"))
r_benefit <- cor(both$warp_pct, both$ae_pct, use = "complete.obs")
cat(sprintf(
"Correlation between warp MISE and alignment error oracle benefit: r = %.2f. ",
r_benefit))Correlation between warp MISE and alignment error oracle benefit: r = 0.37.
if (r_benefit > 0.9) {
cat("The oracle template produces nearly identical benefit patterns for both metrics.\n\n")
} else if (r_benefit > 0.7) {
cat("The benefit patterns are strongly correlated — methods that gain warp accuracy ",
"from the oracle also gain alignment quality, with some exceptions.\n\n")
} else {
cat("The metrics show moderate agreement — oracle template benefits differ ",
"between warp recovery and alignment quality.\n\n")
}The metrics show moderate agreement — oracle template benefits differ between warp recovery and alignment quality.
# Flag any sign disagreements (oracle helps warp but hurts alignment or vice versa)
sign_disagree <- both[sign(warp_pct) != sign(ae_pct)]
if (nrow(sign_disagree) > 0) {
cat(sprintf("Sign disagreements (oracle helps one metric but hurts the other): %d/%d cells.\n\n",
nrow(sign_disagree), nrow(both)))
}Sign disagreements (oracle helps one metric but hurts the other): 14/48 cells.
# Key insight: cc_default warp vs alignment divergence
fda_warp <- benefit_wide[method == "cc_default",
.(warp_med = median(pct_improvement, na.rm = TRUE)), by = condition]
fda_ae <- ae_benefit_wide[method == "cc_default",
.(ae_med = median(pct_improvement, na.rm = TRUE)), by = condition]
fda_both <- merge(fda_warp, fda_ae, by = "condition")
if (any(sign(fda_both$warp_med) != sign(fda_both$ae_med))) {
cat("**Key insight — cc_default metric divergence**: The warp MISE oracle ",
"benefit is negative (estimated pipeline produces better warps due to ",
"iterative refinement), but the alignment error oracle benefit is positive. ",
"This means the true template partially compensates for the worse oracle-mode ",
"warps when computing aligned curves ($\\hat{x}^{\\text{aligned}} = \\hat{\\mu} ",
"\\circ \\hat{h}$): a perfect template offsets some warp error, while the ",
"estimated pipeline's better warps cannot fully compensate for its worse ",
"template. The two metrics thus reveal different facets of the iteration ",
"confound (@sec-limitations).\n")
} else {
cat(sprintf(
"**cc_default** shows consistent sign across metrics: warp MISE median %.0f%%/%.0f%% ",
fda_both[condition == "easy", warp_med], fda_both[condition == "hard", warp_med]))
cat(sprintf(
"vs alignment error %.0f%%/%.0f%% (easy/hard).\n",
fda_both[condition == "easy", ae_med], fda_both[condition == "hard", ae_med]))
}Key insight — cc_default metric divergence: The warp MISE oracle benefit is negative (estimated pipeline produces better warps due to iterative refinement), but the alignment error oracle benefit is positive. This means the true template partially compensates for the worse oracle-mode warps when computing aligned curves (\(\hat{x}^{\text{aligned}} = \hat{\mu} \circ \hat{h}\)): a perfect template offsets some warp error, while the estimated pipeline’s better warps cannot fully compensate for its worse template. The two metrics thus reveal different facets of the iteration confound (Section 7).
How good are the template estimates? This section examines within-method associations between template quality and warp quality in estimated mode.
est_only <- dt[use_true_template == FALSE & failure == FALSE &
method != "landmark_auto"]
ggplot(est_only, aes(y = method, x = template_mise, fill = method)) +
geom_boxplot(outlier.size = 0.3, outlier.alpha = 0.2) +
facet_grid(dgp ~ condition,
scales = "free_x",
labeller = labeller(dgp = dlabs)) +
scale_fill_manual(values = mcols, guide = "none") +
scale_y_discrete(labels = mlabs) +
scale_x_log10() +
labs(y = NULL, x = "Template MISE (log scale, estimated mode only)") +
theme_benchmark(base_size = 9)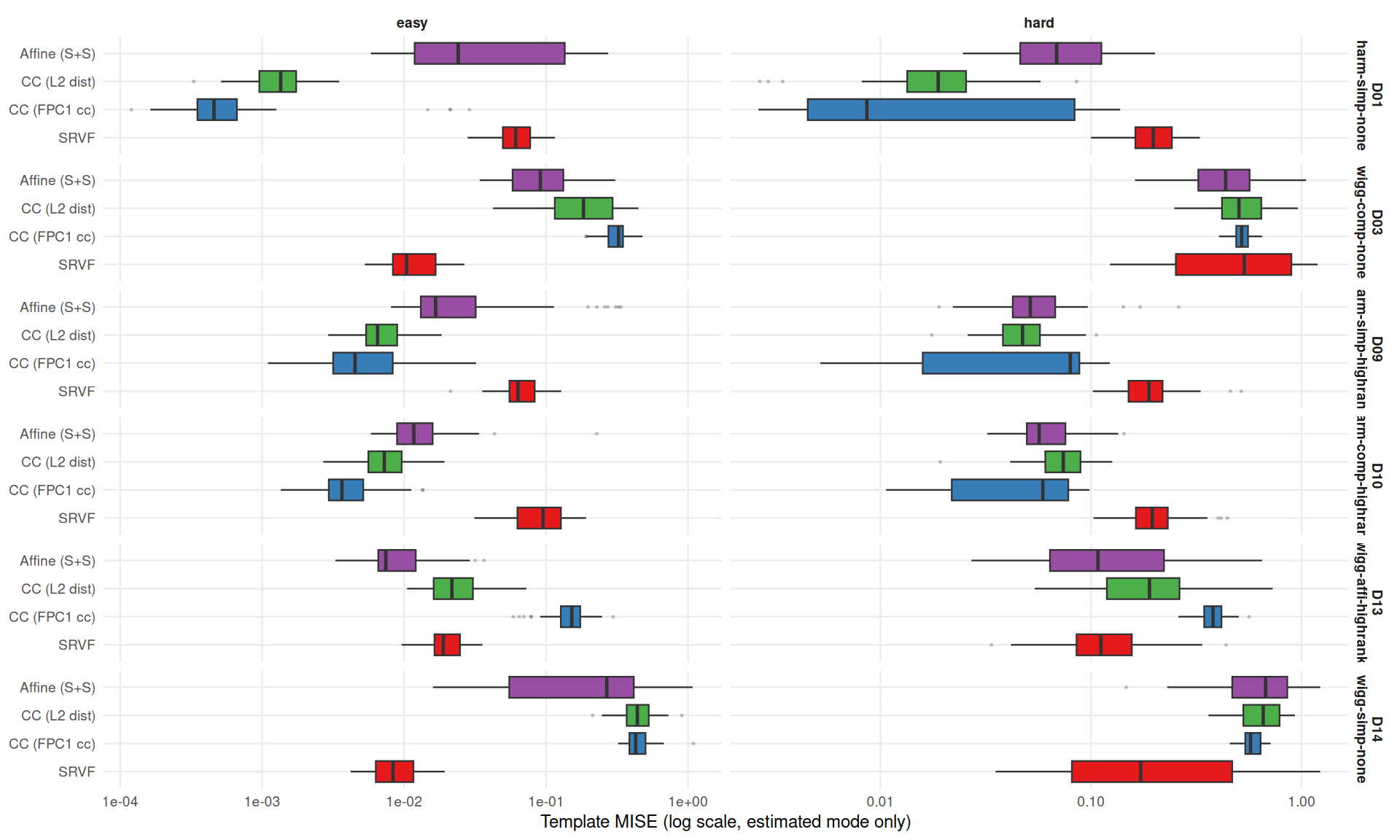
cor_dt <- est_only[,
.(
template_mise = median(template_mise, na.rm = TRUE),
warp_mise = median(warp_mise, na.rm = TRUE),
tmise_q25 = quantile(template_mise, 0.25, na.rm = TRUE),
tmise_q75 = quantile(template_mise, 0.75, na.rm = TRUE),
warp_q25 = quantile(warp_mise, 0.25, na.rm = TRUE),
warp_q75 = quantile(warp_mise, 0.75, na.rm = TRUE)
),
by = .(dgp, method, condition)
]
ggplot(cor_dt, aes(x = template_mise, y = warp_mise, color = method)) +
geom_point(size = 2.5) +
geom_errorbar(aes(ymin = warp_q25, ymax = warp_q75), width = 0, alpha = 0.3) +
geom_errorbarh(aes(xmin = tmise_q25, xmax = tmise_q75), height = 0, alpha = 0.3) +
facet_wrap(~condition) +
scale_x_log10() +
scale_y_log10() +
scale_color_manual(values = mcols, labels = mlabs, name = "Method") +
labs(x = "Template MISE (log scale)", y = "Warp MISE (log scale)") +
theme_benchmark()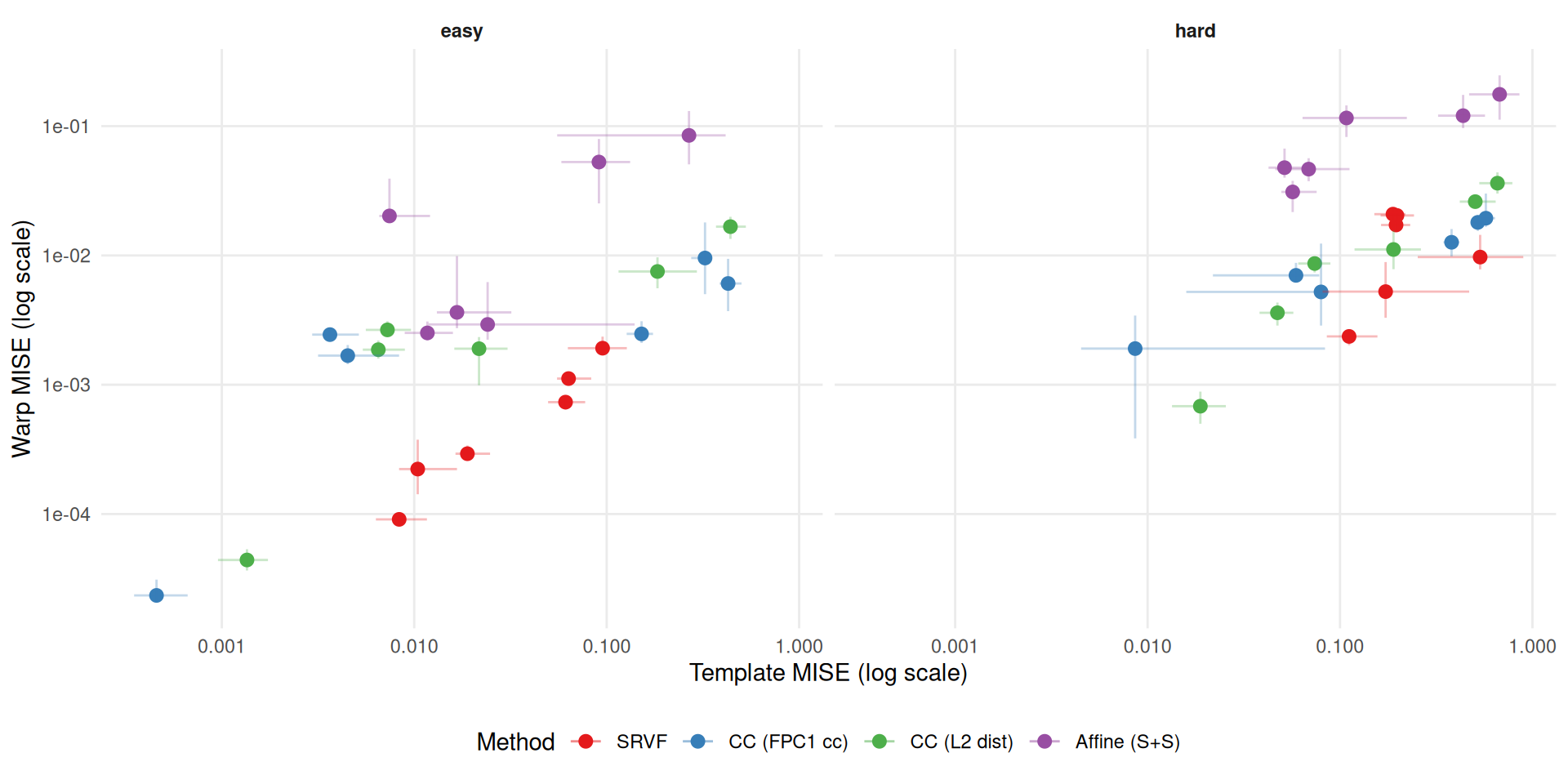
# Overall correlation
cors <- cor_dt[,
.(r = cor(log(template_mise), log(warp_mise), use = "complete.obs")),
by = condition
]
cat("**Correlation between log(template MISE) and log(warp MISE) ",
"(estimated mode, excluding landmarks):**\n\n")Correlation between log(template MISE) and log(warp MISE) (estimated mode, excluding landmarks):
for (i in seq_len(nrow(cors))) {
cat(sprintf("- %s condition: r = %.2f\n", cors$condition[i], cors$r[i]))
}cat("\n")# Per-method correlations
cors_method <- cor_dt[,
.(r = if (.N >= 3) cor(log(template_mise), log(warp_mise),
use = "complete.obs") else NA_real_),
by = .(method, condition)
]
cors_method <- cors_method[!is.na(r)]
if (nrow(cors_method) > 0) {
cat("**Within-method correlations** (each method has 6 DGP points):\n\n")
for (i in seq_len(nrow(cors_method))) {
cat(sprintf("- %s, %s: r = %.2f\n",
mlabs[cors_method$method[i]],
cors_method$condition[i],
cors_method$r[i]))
}
cat("\n")
}Within-method correlations (each method has 6 DGP points):
cat("The overall positive association is partly driven by cross-method ",
"differences in both template and warp quality. Within-method correlations ",
"are more informative for assessing whether template quality causally ",
"affects warp recovery for a given method.\n")The overall positive association is partly driven by cross-method differences in both template and warp quality. Within-method correlations are more informative for assessing whether template quality causally affects warp recovery for a given method.
cat("## max_iter Confound {#sec-max-iter}\n\n")cat("The oracle and estimated pipelines differ in the number of Procrustes ",
"iterations, creating a confound:\n\n",
"| Mode | max_iter | Reason |\n",
"|------|----------|--------|\n",
"| Estimated | 10 | Set in `sim-methods.R` for cc/affine methods |\n",
"| Oracle | 1 | `tf_register()` internally sets `max_iter = 1` when a template is provided |\n\n",
sep = "")The oracle and estimated pipelines differ in the number of Procrustes iterations, creating a confound:
| Mode | max_iter | Reason |
|---|---|---|
| Estimated | 10 | Set in sim-methods.R for cc/affine methods |
| Oracle | 1 | tf_register() internally sets max_iter = 1 when a template is provided |
cat("Each Procrustes iteration re-estimates warps (and, in estimated mode, the ",
"template). Thus the estimated pipeline gets 10 rounds of warp refinement ",
"while the oracle pipeline gets only 1. This means:\n\n")Each Procrustes iteration re-estimates warps (and, in estimated mode, the template). Thus the estimated pipeline gets 10 rounds of warp refinement while the oracle pipeline gets only 1. This means:
cat("- **Positive oracle benefit** (e.g., SRVF) reflects cases where template ",
"accuracy outweighs the loss of iterative refinement.\n")cat("- **Negative oracle benefit** (e.g., cc_default) may partly reflect the ",
"estimated pipeline's advantage from 10 iterations of joint ",
"template-warp optimization.\n\n")cat("A clean ablation (true vs estimated template, both with matched iterations) ",
"would require modifying `tf_register()` to allow `max_iter > 1` with a supplied ",
"template. This is left for a future study revision.\n\n")A clean ablation (true vs estimated template, both with matched iterations) would require modifying tf_register() to allow max_iter > 1 with a supplied template. This is left for a future study revision.
cat("## Scope of Conclusions\n\n")cat("Given the max_iter confound, the oracle comparison is best interpreted as: ",
"**estimated template with iterative refinement** vs **true template with ",
"single-pass alignment**. This is a practically relevant comparison (it reflects ",
"what happens when a user supplies a template to `tf_register()`), but it is not ",
"a pure template-quality ablation.\n\n")Given the max_iter confound, the oracle comparison is best interpreted as: estimated template with iterative refinement vs true template with single-pass alignment. This is a practically relevant comparison (it reflects what happens when a user supplies a template to tf_register()), but it is not a pure template-quality ablation.
cat("Conclusions about the effect of template quality alone should be drawn ",
"primarily from SRVF, where the oracle benefit is consistently positive and large ",
"— indicating that template accuracy dominates even without iterative refinement.\n")Conclusions about the effect of template quality alone should be drawn primarily from SRVF, where the oracle benefit is consistently positive and large — indicating that template accuracy dominates even without iterative refinement.
# Final ranking by oracle benefit
final <- benefit_wide[method != "landmark_auto",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0
),
by = method
][order(-mean_pct)]
cat("**Key findings** (see @sec-limitations for caveats on interpretation):\n\n")Key findings (see Section 7 for caveats on interpretation):
cat("1. **Oracle benefit ranking** (mean % improvement ± SE in warp MISE, pooled over conditions and DGPs):\n\n")for (i in seq_len(nrow(final))) {
cat(sprintf(" - %s: %.0f ± %.0f pp\n",
mlabs[final$method[i]], final$mean_pct[i], final$se_pct[i]))
}cat("\n")# SRVF-specific finding
srvf_benefit <- benefit_wide[method == "srvf",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0
),
by = condition
]
cat(sprintf(
"2. **SRVF benefits most**: Mean oracle benefit %.0f ± %.0f pp (easy) → %.0f ± %.0f pp (hard). ",
srvf_benefit[condition == "easy", mean_pct],
srvf_benefit[condition == "easy", se_pct],
srvf_benefit[condition == "hard", mean_pct],
srvf_benefit[condition == "hard", se_pct]
))cat("SRVF consistently benefits from the true template, with the advantage ",
"growing under harder conditions. This is the cleanest evidence that template ",
"quality matters for warp recovery.\n\n")SRVF consistently benefits from the true template, with the advantage growing under harder conditions. This is the cleanest evidence that template quality matters for warp recovery.
# cc_default finding
fda_def_benefit <- benefit_wide[method == "cc_default",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0,
median_pct = median(pct_improvement, na.rm = TRUE)
),
by = condition
]
cat(sprintf(
"3. **cc_default is condition-dependent**: mean oracle benefit %.0f ± %.0f pp in the easy condition but %.0f ± %.0f pp in the hard condition (medians %.0f%% and %.0f%%). ",
fda_def_benefit[condition == "easy", mean_pct],
fda_def_benefit[condition == "easy", se_pct],
fda_def_benefit[condition == "hard", mean_pct],
fda_def_benefit[condition == "hard", se_pct],
fda_def_benefit[condition == "easy", median_pct],
fda_def_benefit[condition == "hard", median_pct]
))cat("The estimated-template pipeline (with 10 Procrustes iterations) outperforms ",
"the oracle pipeline mainly in the hard regime, suggesting that iterative ",
"refinement and/or co-adaptation of template and warps under criterion 2 compensates ",
"for template estimation error there.\n\n")The estimated-template pipeline (with 10 Procrustes iterations) outperforms the oracle pipeline mainly in the hard regime, suggesting that iterative refinement and/or co-adaptation of template and warps under criterion 2 compensates for template estimation error there.
cat("4. **Landmark sanity**: Oracle benefit is exactly 0%% for landmarks (no template used), validating the experimental design.\n\n")# DGP with largest oracle benefit
max_dgp <- benefit_wide[method != "landmark_auto"][which.max(pct_improvement)]
cat(sprintf(
"5. **Largest oracle benefit**: %s on %s (%s condition): %.0f%% improvement.\n\n",
mlabs[max_dgp$method], max_dgp$dgp, max_dgp$condition, max_dgp$pct_improvement
))cat("6. **Implication for `tf_register()`**: The asymmetry between methods suggests ",
"that (a) SRVF registration would benefit most from better template initialization ",
"or multi-resolution estimation, and (b) cc_default's criterion 2 benefits from ",
"iterative joint optimization, making the number of Procrustes iterations an ",
"important tuning parameter for this method.\n\n")tf_register(): The asymmetry between methods suggests that (a) SRVF registration would benefit most from better template initialization or multi-resolution estimation, and (b) cc_default’s criterion 2 benefits from iterative joint optimization, making the number of Procrustes iterations an important tuning parameter for this method.# Alignment error finding
ae_final <- ae_benefit_wide[method != "landmark_auto",
.(
mean_pct = mean(pct_improvement, na.rm = TRUE),
se_pct = if (.N > 1) sd(pct_improvement, na.rm = TRUE) / sqrt(.N) else 0
),
by = method
][order(-mean_pct)]
cat("7. **Alignment error tells a different story** (@sec-alignment-error): ",
"Oracle benefit is positive for all methods when measured by alignment error, ",
"even cc_default. ")fda_ae_summary <- ae_final[method == "cc_default"]
cat(sprintf(
"cc_default's alignment error oracle benefit is %.0f ± %.0f pp (positive), while its ",
fda_ae_summary$mean_pct, fda_ae_summary$se_pct))cc_default’s alignment error oracle benefit is 19 ± 9 pp (positive), while its
cat("warp MISE oracle benefit is negative. The true template compensates for worse ",
"oracle-mode warps when computing aligned curves, revealing that the two metrics ",
"capture different aspects of the iteration confound.\n")warp MISE oracle benefit is negative. The true template compensates for worse oracle-mode warps when computing aligned curves, revealing that the two metrics capture different aspects of the iteration confound.